
Tagging Shenoute by Caroline T. Schroeder & Amir Zeldes is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

Many thanks to the people and institutions who made this possible: my collaborator Dr. Amir Zeldes; Tito Orlandi, Stephen Emmel, Janet Timbie, and Rebecca Krawiec who have freely given their labor and their advice; and funding agencies of the National Endowment for the Humanities and the German Federal Ministry of Education and Research. I’m also pleased that this year Rebecca Krawiec along with Christine Luckritz Marquis and Elizabeth Platte will be helping to expand our corpus of digitized texts.
Two years ago, I gave a NAPS paper entitled, “Shenoute of Atripe on the Digital Frontier,” in which I explored – and despaired – of challenges to digital scholarship in early Christian studies, especially Coptic. I posed important questions, such as, “Why don’t my web pages make the supralinear strokes in Coptic appear properly?” and “Why do I only have 50 followers on Twitter?”
I am pleased to report that I have in fact solved both of those problems. And today I want to take you on a tour into the weeds of digital Coptic: how to create a data model for computational research in Coptic; the requirements for visualizing and searching the data; and what you can do with this all once you’ve got it.
Today I’m going to get technical, because over these past two years I’ve come to learn two things:
1. Digital scholarship is about community—the community that creates the data, contributes to the development of standards for the creation of that data, and conducts research using the data. In other words, my work won’t succeed if I don’t drag all of you along with me.
2. The truth is not in there (i.e., you might be thinking, “What is she doing talking about “data” – she did her Ph.D. at Duke in the 1990s?!). In case you came to this paper wondering if I’ve abandoned my Duke Ph.D. post-modern, Foucauldian, patented Liz Clark student cred for some kind of positivist, quantitative stealth takeover of the humanities, well HAVE NO FEAR. The true truth is not in some essentialized compilation of “the data.” As with traditional scholarship, our research questions determine how we create our dataset, and how we curate it, annotate it is already an act of interpretation. (I owe Anke Lüdeling for helping me think through this issue.)
So please, take my hand and take the red pill, not the blue pill, and jump into the data.

Our project is called Coptic Scriptorium, and in a nutshell, it is designed as an interdisciplinary, digital research environment for the study of Coptic language and literature. We are creating technologies to process the language, a richly annotated database of texts formatted in part with these technologies, texts to read online or download, documentation, and ultimately a collaborative platform where scholars and students will be able to study, contribute, and annotate texts. It is open source and open access (mostly CC-BY, meaning that you can download, reuse, remix, edit, research, and publish the material freely as long as you credit the project.
We also invite any of you to collaborate with us. Consider this presentation an open invitation. Our test case was a letter of Shenoute entitled Abraham Our Father, and we’ve since expanded to include another unnamed text by Shenoute (known as Acephalous Work 22 or hereafter A22), some Sahidic Sayings of the Desert Fathers, two letters of Besa, and a few chapters of the Gospel of Mark.
I’ve entitled this paper, “Tagging Shenoute” for two reasons. First, “tagging” refers to the process of annotating a text. To conduct any kind of search or computational work on a corpus of documents, you need to mark them up with annotations, sometimes called “tags.” They might be as simple as tagging an entire document as being authored by Shenoute, or as complex as tagging every word for its part of speech (noun, verb, article, etc.) or its lemma (the dictionary headword for words that have multiple word forms) Second, because the pun with the child’s game of tag was too rich to pass up. The Abba himself disdained children’s play and admonished the caretakers of children in his monastery not to goof around:
As for some people who have children who were entrusted to their care, if it is of no concern to them that they live self-indulgently, joking with them, and sporting with them, they will be removed from this task. For they are not fit to be entrusted with children. It is in this way also with women who have girls given to them.”
Shenoute, Canons vol. 9, DF 186-87 in Leipoldt 4:105-6
And finally, I was inspired by a conversation between two senior Coptic linguists at the Rome 2012 Congress for the International Association of Coptic Studies. When I told them about our nascent project, one replied something along the lines of, “I would not dare to think that Shenoute would allow himself to be tagged!” And the riposte from the other: “And I would not presume to speak for Shenoute!” All of this is to subversively suggest, that despite Shenoute’s own words, he can be fun. While annotation is serious work, there is also an element of play: playing with the data, and pleasure in the text.
The premise of our project is to facilitate interdisciplinary research, to develop a digital environment that will be of use to philologists, historians, linguists, biblical scholars, even paleographers. To that end, we have dared to tag Shenoute in quite a variety of ways:
- Metadata: information about text, author, dating, history of the manuscript, etc.
- Manuscript or document structure: page breaks, column breaks, line breaks, damage to the manuscript, different ink colors used, text written as superscript or subscript, text written in a different hand….
- Linguistic: part of speech (noun, verb, article, stative verb, relative converter, negative prefix, etc.), language of origin (Greek, Hebrew, Latin…), lemmas (dictionary headwords for words with multiple forms
- Translations
With hopefully more to come: biblical citations, citations and quotations to other authors, named entities with data linked to other open source projects on antiquity, source language for texts in Coptic translation (e.g., Apophthegmata Patrum and Bible).
We also must be cautious and discerning, on the lookout for the demon of all things shiny and new. As Hugh Cayless writes on the blog for the prosopographical project SNAPDRGN,
“In any digital project there is always a temptation to plan for and build things that you think you may need later, or that might be nice to have, or that might help address questions that you don’t want to answer now, but might in the future. This temptation is almost always to be fought against. This is hard.”
Hugh Cayless, “You Aren’t Gonna Need It” 22 May 2014
Digital scholarship in Coptic must develop annotation standards in conversation with existing conventions in traditional, print scholarship, as well as digital standards used by similar projects on the ancient world and ancient texts. For Shenoute, this means using as titles of texts the incipits delineated by Stephen Emmel in his book Shenoute’s Literary Corpus, manuscript sigla developed by Tito Orlandi and the Corpus dei Manoscritti Copti Letterari as well as id numbers for manuscripts established by the online portal Trismegistos, and part-of-speech tags based on Bentley Layton’s Coptic Grammar.
In the digital world, in addition to Trismegistos, the emerging standard for encoding manuscript information for ancient papyri, inscriptions, and manuscripts is the subset of the Text Encoding Initiative’s XML tagset known as EpiDoc. The Text Encoding Initiative is a global consortium of scholars who have established annotation standards (including a comprehensive set of tags) for marking up text for machine readability. XML stands for Extensible Markup Language, and is used more widely in computer science, including in commercial software. EpiDoc is a subset of TEI annotations used especially by people working in epigraphy or on ancient manuscripts in a variety of languages. Patristics scholars might be familiar with it because the papyrological portal papyri.info uses EpiDoc markup to annotate its digital corpus.
So, this is a lot of information – what does the data actually look like? Coptic poses some unique challenges.

To get from base text, to annotated corpora, there are a lot of steps: basic digitization of the text, encoding the manuscript information, ensuring Coptic word forms make sense properly, separating those bound groups into morphemes, normalizing the spelling so you can do genuine searching, and tagging for various annotations. I’m going to briefly go through most of these issues.
Before you can even begin to think about tagging, the data must be in a digital format that can be used and searched: typed in Unicode (UTF8) characters and in recognizable word forms. Many of us in this room probably have various files on our computers with text we keyed into Microsoft Word (or dare I say, WordPerfect?) in legacy fonts. We have developed converters ourselves for a couple of different legacy fonts. But keying in the text is only one piece of the puzzle; users of the data must be able to see the characters on their computers, ideally even if they don’t have a Coptic font or keyboard installed, or on their mobile devices.

So we created an embedded webfont that is installed on our website and inside our search and visualization tool. We’ve even embedded a little Coptic keyboard into the search tool, so that you can key in Coptic characters yourself if your device isn’t capable.
Those of you who have studied Coptic know that it is different from Greek or Latin, in that it is an agglutinative language.

Multiple different morphemes, each with different parts of speech, are plugged together like Legos to create “words,” or as Layton describes them, “bound groups.” When you search Coptic, you might not want to search bound groups but rather the individual morphemes within them. That means, when you digitize the text, you need to be attentive to the morphemes and word segmentation. This process of breaking a text into its constituent parts is called “tokenization”; the token is the smallest possible piece of data you annotate. In English texts, it’s often a word.
There are two problems with Coptic.
– First, the concept of words is complex in Coptic
– Second, annotations overlap parts of words. For example, in a manuscript a line might break in the middle of a word.
Here are some examples. When we say Coptic is agglutinative, we mean that what we might think of as “words” are really bound groups of morphemes, as seen here in these two examples.
 We’ve color-coded each separate morpheme, so that you can see that each one of these examples is a combination of seven or eight components. To complicate matters, scholars use different conventions to bind these morphemes into words in print editions. We follow Layton’s guidelines for visualizing or rendering Coptic bound groups.
We’ve color-coded each separate morpheme, so that you can see that each one of these examples is a combination of seven or eight components. To complicate matters, scholars use different conventions to bind these morphemes into words in print editions. We follow Layton’s guidelines for visualizing or rendering Coptic bound groups.
But we also need not only to see or visualize words as bound groups but also to automate the taking apart of these bound groups. Our tools cannot yet handle text as you might see it in a manuscript, with scriptio continua.  But, we have automated segmenting bound groups into morphemes, thanks in part to a lexicon that Tito Orlandi graciously gave us, which sped up our work by about a year.
But, we have automated segmenting bound groups into morphemes, thanks in part to a lexicon that Tito Orlandi graciously gave us, which sped up our work by about a year.
But we need to dig deeper into our data than morphemes, because we might need to annotate on a level that’s even smaller than the morpheme. If you want to mark up the structure of the manuscript – the line breaks, oversized letters, letters written in different ink colors, etc., you need to annotate on the level of parts of morphemes or individual letters.
 As in this example, where things that appear in the middle of a morpheme (such as the oversized janja in the middle of the word pejaf) might need to be tagged – size, line break, etc. So you need to annotate on a more granular level than “words” or “morphemes.”
As in this example, where things that appear in the middle of a morpheme (such as the oversized janja in the middle of the word pejaf) might need to be tagged – size, line break, etc. So you need to annotate on a more granular level than “words” or “morphemes.”
So, now we’ve already got a ton of different ways to tag our data, and we’re not done yet. Lots of other tagging or annotations that you might want to make and use for research. What you do NOT what to have to do is to write this all up manually using actual xml tags in what is called inline markup.

Instead if you markup your data in multiple layers, or what is known as mulit-layer standoff markup, you can make more sense of it and tag your data much more easily.
 Here you can see the smallest level of data, the token layer, at the top. The second layer shows the morpheme segments, aligned with the tokens but those two at the end are merged into one, because it is one term – Abraham. Line three gives you the bound groups, line four shows you line breaks. Here you see the line ends in the middle of Abraham. Line 5 shows column breaks, and six page breaks.
Here you can see the smallest level of data, the token layer, at the top. The second layer shows the morpheme segments, aligned with the tokens but those two at the end are merged into one, because it is one term – Abraham. Line three gives you the bound groups, line four shows you line breaks. Here you see the line ends in the middle of Abraham. Line 5 shows column breaks, and six page breaks.
Moreover, you want to automate as much of your annotation as possible. We have at least semi-automated normalizing spelling, which eliminates diacritics and supralinear strokes, normalizes spelling variants, deals with abbreviations, and so forth. Normalization is essential both for search and for further automated annotations. We’ve also semi-automated annotations for language of origin of words in a text, and we are developing a lemmatizer, which will match each word with its dictionary head word.
Finally we’ve developed a part of speech tagger, which is is a natural language processing algorithm. It learns as it processes more data, based on patterns and probabilities. We have two sets of tags – coarse, which will just tag all nouns as nouns, for example – and fine – which will tag proper nouns, personal subject pronouns, personal object pronouns, etc.
 And so now your data looks like this:
And so now your data looks like this:
 You’ve preserved all your information. By making everything annotations – even spelling normalization – you don’t “lose” information. You just annotate another layer.
You’ve preserved all your information. By making everything annotations – even spelling normalization – you don’t “lose” information. You just annotate another layer.
So, what can you do with this?
1. Basic search for historical and philological research. Below is a screen shot of the search and visualization tool we are using, ANNIS. ANNIS was developed originally for computational linguistics work, and we are adapting it for our multidisciplinary endeavor. Here I’ve searched for both the terms God and Lord in Shenoute’s Abraham Our Father.
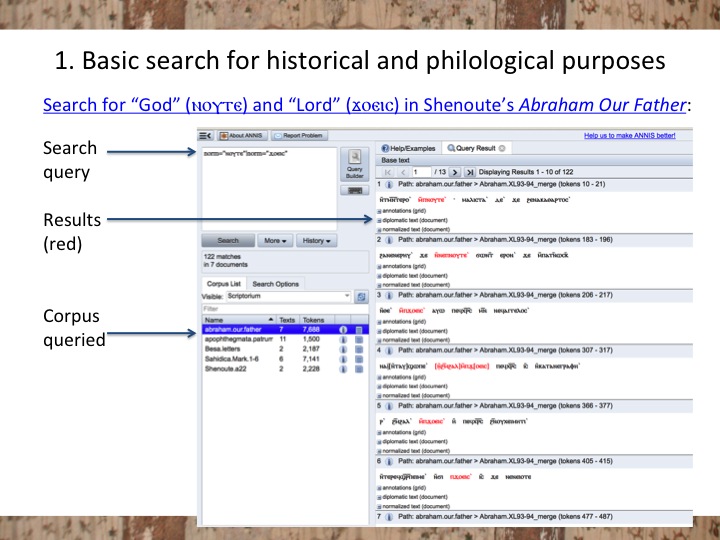 The query is on the upper left, corpus I’ve selected is in the lower left, and the results on the right.
The query is on the upper left, corpus I’ve selected is in the lower left, and the results on the right.
You can export your results or select more than one text to search:
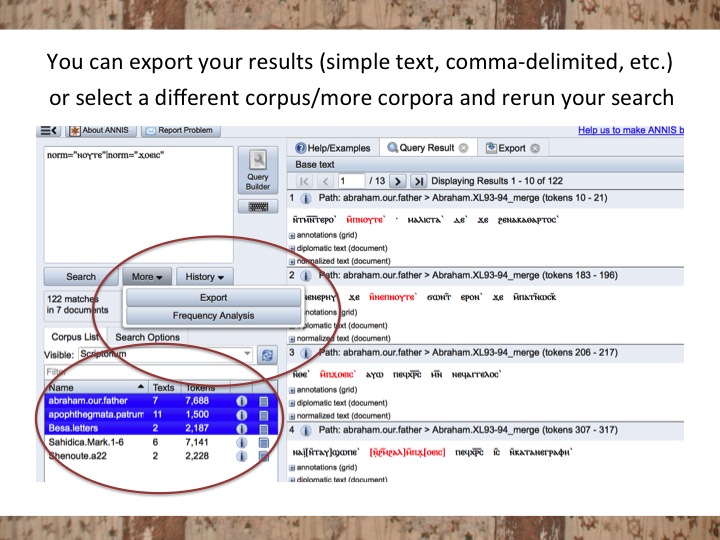 And if you click on a little plus sign next to “annotations” under any search result, you can see all the annotations for that result.
And if you click on a little plus sign next to “annotations” under any search result, you can see all the annotations for that result.
 So, noute is a noun, it’s part of this bound group hitmpnoute, it’s in page 518 of manuscript YA, etc.
So, noute is a noun, it’s part of this bound group hitmpnoute, it’s in page 518 of manuscript YA, etc.
You can also read the text normalized or in the diplomatic edition of the manuscript inside ANNIS:

Or if you already know the texts you want to read, you can access them easily as stand-alone webpages on our main site (coptic.pacific.edu: see the HTML normalized and diplomatic pages of texts).
2. Linguistics and Style. Here, I’ve told ANNIS to give me all the combinations of three parts of speech and the frequencies those sequences occur:

This is known as a “tri-gram” – you’re looking for sequences of three things. I didn’t tell it any particular three parts of speech, I said, give me ALL sequences of three. And then I generated the frequencies. Note: everything I am presenting here is raw data, designed primarily to GENERATE and EXPLORE research questions, not to answer them in a statistically rigorous way. This is raw data.
What do we learn?
The most common combination of three grammatical categories is the preposition + article + noun (“in the house”) across ALL the corpora – this is #1. Not a surprise if you think about it.
 Also, you’ll notice some distinct differences in genre: the second most common tri-gram in the Apophthegmata Patrum is the Past tense marker+the subject personal pronoun+verb –this fits with the Sayings as a kind of narrative piece (3.66% of all combinations). Similarly, for Mark 1-6– the second most common tri-gram is Past tense marker +personal pronoun subject + verb (4.03% of trigrams). Compare that to Besa, where this combination is the 4th most common tri-gram (2.1% of trigrams), or Shenoute, with .91% (A22, 14th most common trigram) & 1.52% (also 4th most common) in Abraham Our Father. (My hunch is this tri-gram probably skews HIGH in Abraham compared to its frequency overall in Shenoute, since there are so many narrative references to biblical events in Abraham Our Father.)
Also, you’ll notice some distinct differences in genre: the second most common tri-gram in the Apophthegmata Patrum is the Past tense marker+the subject personal pronoun+verb –this fits with the Sayings as a kind of narrative piece (3.66% of all combinations). Similarly, for Mark 1-6– the second most common tri-gram is Past tense marker +personal pronoun subject + verb (4.03% of trigrams). Compare that to Besa, where this combination is the 4th most common tri-gram (2.1% of trigrams), or Shenoute, with .91% (A22, 14th most common trigram) & 1.52% (also 4th most common) in Abraham Our Father. (My hunch is this tri-gram probably skews HIGH in Abraham compared to its frequency overall in Shenoute, since there are so many narrative references to biblical events in Abraham Our Father.)
Whereas a marker for Shenoute’s style is the relative clause. Article + noun + relative converter occurs .91% of the time in Acephelous Work #22 and .76% in Abraham. But in Mark, it’s the 33rd most common combination, and occurs .55% of the time. In the Apophthegmata Patrum, it occurs .44% of the time (the 40th most common combination).
 Some of you are probably thinking, “Wait a minute, what is this quantitative analysis telling me that I don’t already know. Of course narrative texts use the past tense! And Shenoute’s relative clauses have been giving me conniption fits for years!” But actually, having data confirm things we already know at this stage of the project is a good thing – it suggests that we might be on the right track. And then with larger dataset and better statistics, we can next ask other questions about, say, authorship, and bilingualism or translation vs native speakers. For example: A) How much of the variation between Mark and the AP on the one hand, and Shenoute and Besa on the other can be explained by the fact that Mark and the AP are translations from the Greek? Can understanding this phenomenon – the syntax of a translated text – help us study other texts for which we only have a Coptic witness and resolve any of those “probably translated from the Greek” questions arise about texts that survive only in Coptic? B) Shenoute is reported to have lived for over 100 years with a vast literary legacy that spans some eight decades. Did he really write everything attributed to him in those White Monastery codices? Can we use vocabulary frequency and style to attribute authorship to Coptic texts?
Some of you are probably thinking, “Wait a minute, what is this quantitative analysis telling me that I don’t already know. Of course narrative texts use the past tense! And Shenoute’s relative clauses have been giving me conniption fits for years!” But actually, having data confirm things we already know at this stage of the project is a good thing – it suggests that we might be on the right track. And then with larger dataset and better statistics, we can next ask other questions about, say, authorship, and bilingualism or translation vs native speakers. For example: A) How much of the variation between Mark and the AP on the one hand, and Shenoute and Besa on the other can be explained by the fact that Mark and the AP are translations from the Greek? Can understanding this phenomenon – the syntax of a translated text – help us study other texts for which we only have a Coptic witness and resolve any of those “probably translated from the Greek” questions arise about texts that survive only in Coptic? B) Shenoute is reported to have lived for over 100 years with a vast literary legacy that spans some eight decades. Did he really write everything attributed to him in those White Monastery codices? Can we use vocabulary frequency and style to attribute authorship to Coptic texts?
3. Language, loan words, and translation practices. We can also study loan words and translation practices. Quickly let’s take a look at the frequency of Greek loan words in the five sets of texts:
 In Abraham Our Father, 4.71% of words are Greek; Mark 1-6: 6.33%; A22: 5.44%; Besa: 5.82%; AP: 4.25%. The texts are grouped on the graph roughly by the size of the corpus – Mark 1-6 is closer in size to Abraham Our Father, and the others are very small corpora. What’s interesting to me is the Apophthegmata Patrum number. Since it’s a translation text, I’d expect this figure to be higher, more like Mark 1-6.
In Abraham Our Father, 4.71% of words are Greek; Mark 1-6: 6.33%; A22: 5.44%; Besa: 5.82%; AP: 4.25%. The texts are grouped on the graph roughly by the size of the corpus – Mark 1-6 is closer in size to Abraham Our Father, and the others are very small corpora. What’s interesting to me is the Apophthegmata Patrum number. Since it’s a translation text, I’d expect this figure to be higher, more like Mark 1-6.
4. Scriptural references and other text reuse. Is it also possible to use vocabulary frequencies to find scriptural citations? The Tesserae project in Buffalo is working on algorithms to compare two texts in Latin or two texts in Greek to try to identify places where one text cites the other. Hopefully, we will be able to adapt this for Coptic one day.
 In the Digital Humanities, “distant reading” has become a hot topic. Distant reading typically means mining “big data” (large data sets with lots and lots of texts) for patterns. Some humanists have bemoaned this practice as part of the technological takeover of literary studies, the abandonment of close reading in favor of quantitative analyses that don’t require you ever to actually read a text. Can distant reading also serve some very traditional research questions about biblical quotations, authorship identification, prosopography, or the evolution of a dialect?
In the Digital Humanities, “distant reading” has become a hot topic. Distant reading typically means mining “big data” (large data sets with lots and lots of texts) for patterns. Some humanists have bemoaned this practice as part of the technological takeover of literary studies, the abandonment of close reading in favor of quantitative analyses that don’t require you ever to actually read a text. Can distant reading also serve some very traditional research questions about biblical quotations, authorship identification, prosopography, or the evolution of a dialect?
This project still has a lot to do. We need to improve some of our taggers, create our lemmatizer, link our lemmas to a lexicon, provide universal references so that our texts, translations, and annotations can be cited, and possibly connect with other linked data projects about the ancient world (such as Pelagios and SNAPDRGN).
For today, I hope to have shown you the potential for such work, the need for at least some of us to dive into the matrix of technical data as willingly and as deeply as we dive into depths of theology and history. And also, I invite you to join us. If you have Coptic material you’d like to digitize, if you have suggestions, if you would like to translate or annotate a text we already have digitized, consider this an invitation. Thank you.
